Credit – who doesn’t want to have lots of it at the bank
According to Wikipedia the short definition in finance terms is :
Credit is the trust which allows one party to provide resources to another party where that second party does not reimburse the first party immediately (thereby generating a debt, but instead arranges either to repay or return those resources (or other materials of equal value) at a later date
In Fibre Channel it’s not much different. During initialization of a port they both provide the remote party a certain amount of resources (buffer credits) which tell the remote party it is allowed to send this x amount of frames. If this credit is used up the sending port is no longer allowed to send anymore frames. The receiving port get the frame and when the first couple of bytes have been read it will send a so called R_RDY to the sending port telling him to increase his credit by one. This part I described before.
A short side note is that this is normal operation in a class 3 FC network. A class 1 network uses End-to-End credits but this is hardly ever used.
Taking the above into account it shows that all links in a FC network use this method for flow control. This is thus not only restricted to HBA, Disk, Tape and switchports but also internally within switches this method is used. The most explanatory way of showing this is when you have a blade based chassis where ports in one blade need to transfer frame to a port on another blade. Basically this means that the frame will traverse two more hops before it reaches that port. If you have a small switch with only one ASIC all frames will be short routed in that same ASIC.
As an example.
A Brocade 5100 has a single 40-port Condor2 ASIC which means all 40 front-end ports are connected to this same chip.
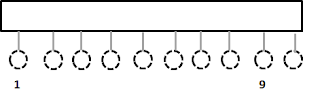
Any frame traversing from port 1 to port 9 will be switched inside that same chip. Sounds obvious. This also means there are only two points of B2B flow control and that is between the devices connected to both port 1 and 9.
When looking at a Brocade 5300 there is completely different architecture.

This switch has 5 GoldenEye2 ASICS which serve 80 front-end ports (16 each) and 4 back-end ASIC which serve as interconnect between those 5 front-end ASICs. Each GoldenEye2 chips has 32 8G ports and each front-end to back-end link is connected with a single 4-port trunk which allows for any-to-any 1:1 subscription ratio.
If we look at this picture and have an HBA connected to port 1 and a storage device connected to port 45 you’ll see that the frame has to traverse 2 additional hops from ASIC 1 to a back-end ASIC and from there onward to ASIC 5. (Internal links are not counted as an official “hop-count” so it is not calculated on fabric parameters.) As you have seen in my previous post when a link error between an end-device and a switch port surfaces causing credit depletion the switch or device will reset the link, bring back the credit count to login values and the upper layer protocol (ie SCSI) has to retry the IO. There is no such mechanism on back-end ports. You might argue that given the fact this is all inside the switch and no vulnerable components like optical cables can cause corrupt primitives hence lost R_RDY’s are impossible. Unfortunately this is not entirely true. There might be circumstances where front-end problems might propagate to the back-end. This is often seen during very high traffic times and problematic front-end ports. The result is that one or more of those back-end links have a credit stuck at zero which basically means the front-end port is no longer allowed to send frames to the back-end therefore causing similar problems with high latency and elongated IO recovery times. The REALLY bad news is that there is (now : “was”) no recovery possible besides bouncing the entire switch. (By bouncing I mean a reboot and not throwing it on the floor hoping it will return in your hands. Believe me, it wont. At least not in one piece)
All the Brocade OEM’s have run into situations like this with their customers and especially on larger fabrics with multiple blade based chassis with hundreds of ports connected you can imagine this was not a good position to be in.
In order to fix this Brocade has implemented some new logic, albeit proprietary and not FC-FS standard, which allows you to enable a feature to turn on back-end credit checking. In short what it does is that it monitors the number of credits on each of these back-end links, if the credit counter stays at less than the number of credits negotiated during login for the E_D_TOV timeframe and no frames has been sent during that timeframe, the credit recovery feature will reset the link for you in a similar fashion as the front-end port do, and it will resume normal operation.
The way turn on this feature is also part of the bottleneckmon command:
bottleneckmon –cfgcredittools -intport -recover onLrOnly
To be able to use this command you have to be at least at FOS level 6.3.2d, 6.4.2a or higher.
The latest FOS releases also have a manual check in case you might suspect a stuck credit condition.
As soon as you’ve enabled this feature (which I suggest you do immediately) you might run into some new errorcodes in the eventlog. When a lost credit condition is observed you will see a C2-1012 which shows something similar like this:
Message , [C2-1012], ,, WARNING, ,S,P(): Link Timeout on internal portftx= tov= (>)vc_no= crd(s)lost= complete_loss:. (s)>
If this happens due to a problem on the back-end whereby a physical issue might be the problem the cause is most likely an increased bit error rate causing the same encoding/decoding errors. As shown before this will also corrupt R_RDY primitives. In addition to the C2-1012 you will also see a C2-1006 sometimes followed by a C2-1010
Message , [C2-1006], ,, WARNING, ,S,C: Internal link errors reported, no hardware faultsidentified, continuing monitoring: fault1:, fault2:thresh1:0x.
Message , [C2-1010], ,, CRITICAL, ,S, C: Internal monitoring has identified suspecthardware, blade may need to be reset or replaced: fault1:,fault2: th2:0x.
There are some more errorcodes which outline specific conditions but I refer to the Brocade Message Reference guide for more info.
We talked a bit of frameflow and latency in the previous articles. Besides corruption due to a high bit-error rate you might be running into a high latency device which basically is a device which is slow in returning credits. Sometimes this is by design as firmware engineers might use this as a way to throttle incoming traffic which they are unable to offload onto the PCI bus or there is some other problem inside the system itself which causes elongated handling of data by which the HBA cannot send the data quick enough to memory via RDMA or to the CPU for further handling.
Although it is a choice of the firmware and design engineers normally the response time to send back buffercredits should be virtually instantaneous.
To to give you a feeling of the timing an average R_RDY reponse time is around 1 to 5us. If you have a older network with low performance links this might increase to around 50us or sometimes higher.
 |
| FC trace |
As you can see (i hope you have good eyesight) the R_RDY is returned within 2us of the dataframe being sent. This includes the reception of the first 24 bytes of the frame and the routing decision time-span the switchport has made. So all in all pretty quick.
On somewhat slower equipment it looks a bit like this:

(The time between the frame and R_RDY shows a delta of 10.5us)
When you have a latency problem where the device is realy slow in returning credits this time is far greater than shown above.
The above picture come from a pretty expensive FC analyser and I don’t expect you to buy one (although it’s a pretty cool toy to get to the nitty gritty of things.) If you run into a performance problem where you don’t see any obvious physical issue you might have ran into a slow drain device. With the later FOS versions from Brocade there is a counter called er_tx_c3_timeout. This counters shows how many time a frame has been discarded due to upstream credit shortages. If this is an F-port than the device connected to this port is a very candid suspect of mucking up your storage network. If this is an ISL then you will need to look at devices that are more upstream of this port connected to other switches, routers or other equipment.
As always be aware that all these counters are cumulative and will just wrap after a while. You will have to establish a new baseline and then monitor for any counter to increase. The counter I mentioned above is also part of the porterrshow output since FOS version 7 which makes it very easy to determine such a condition.
I hope the blog posts in this series have helped a bit to explain how FC flow control work, how it operates in normal environments and also what might happen if it doesn’t go as planned plus the ways to prevent and solve such conditions.
Let me know if you want to know about this or any other topic and I’ll see what I can produce.
Regards,
Erwin








