In some of my previous post I have outlined the reasons and consequences of errors on a link. There are multiple locations where a bit may flip from a 0 to a 1 or reverse. CRC errors, encoding errors, synchronisation and link failures are the usual symptoms and may lead to corrupted frames, primitives signals and primitive sequences. In the end they will lead to some sort of IO error or performance problem.
So where do these errors come from? The easiest ones to solve are those ones of a physical nature. Broken cables, wrongly fitted connectors, unclean connection points due to dust or incorrect handling of the cables. The ones who do not fall into these categories are much more difficult to detect. If you have checked and fixed your physical part of the puzzle we may need to dive in somewhat deeper into the “not-so-obvious” side of the fence and this is where it gets most interesting as well as complicated.
As you most likely know all current transmission protocols use a serial transmission link. This goes from 100Gb Ethernet to your SATA disk channel in your PC. Obviously Fibre Channel uses a serial transmission as well. As with many protocols the FC protocol is build upon layers and the serial transmission characteristics reside on the FC0 and FC1 layer.
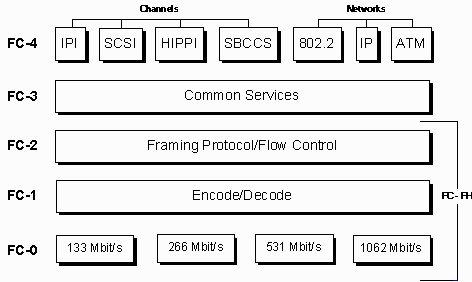 |
| A somewhat older picture of the FC stack |
The above picture more or less outlines the stack. Of course the speeds and feeds have increased but the general operations have remained the same.
So if the physical side is out of the way what could then cause a bit to flip. Well, pretty often a degraded SFP or incorrect settings on an ASIC may cause interference. When you look at the defect list from Brocade/Cisco and other vendors you\’ll see so now and they defects popping up where they have adjusted so called “SERDES settings”. SERDES stands for SERializer/DESerializer which inherently implies they must be doing something on the chip which serialises and de-serialises the data stream. To go further into this we need to have a look how a basic flow of bits is being sent from the ASIC through the SFP onto the wire.
First you start of with 8 bits and this runs thru the encoder chip. Here the byte is split into two blocks of 5 and 3 bits after which an XOR mathematical calculation takes place and this results into 4 and 6 bit sub-blocks which are then glued back together so you end up in 10 bits. These still reside in a parallel way in a chip and thus it will be sent to the serializer. Based upon hardware implementation a FIFO buffer might in between these two. After it has passed the serializer it will be passed onto the SFP driver which converts it from an electrical to optical signal and puts in on the wire.
On the receiving side things are a bit more complicated. First of all it needs to align the incoming bitstream to a meaningful piece of information and therefore it has to align the clock speed to that bit-stream. Given the fact a 10-bit transmission character can hold more information then a 8 bit byte (duhh) means we end up with some additional characters which we can utilize. The most important one is the K28.5 character (also called a comma) which is send on the very first character of each frame as well as all primitive signals or ordered sets. (IDLE/R_RDY/NOS/OLS/LR etc..) Remember that FibreChannel is WORD aligned and each word consists of 4 transmission characters ie 40-bits. A primitive signal is thus 40 bits of which the first character start with K28.5 and then 3 “data” characters Dxx.x.
Depending on the current running disparity the K28.5 looks like 0011111010 on a negative RD or like 1100000101 on a positive RD. These two characters do never show up anywhere else in a bit-stream irrespective of payload. So when the very distinctive K28.5 arrives at the ingress port the receiver knows the exact point of which to align the synchronisation of the stream. The reason why this is needed is because there will always be a slight discrepancy on the frequency of the clocks between the remote and local side. The alignment of the clock via the bit-stream is a very effective way of achieving very high data-rates with accurate bit and word synchronisation. This would never have been possible with parallel link such as in the “old” SCSI days.
The de-serialized bitstream is thus sent a chip which effectively does the comma realignment after which it can be pushed into the decoding chip so the 10-bit transmission character can now be converted back to an 8-bit byte by applying the same XOR algorithm, in an inverse manner, which was used to encode the byte in the first place. After that is done the byte will be put into a, so called, elastic buffer. This nifty piece of chip is required to balance the ingress rate of which the bitstream arrives and the rate of which the ASIC or FPGA is able to pull the data from this interface. If the ASIC is able to pull the data quicker out of the interface than the interface can deliver the bit stream you end up in a so called underrun. If, on the other hand, the interface is delivering the data quicker than the ASIC can pull it out you may end up in an overrun. This is where the flexibility of the FC protocol comes into play with regards to fill-words. Basically it means that according to the standard each transmitting interface shall send at least 6 fill-words (either IDLE or ARB(FF))between two frames. The remote side however only needs to detect 3 to detect an inter-frame gap so it has a 3 word playroom to either add fillwords into the elastic buffer to prevent underrun or remove fillword in the event of overrun.
On 10GFC and 16GFC the 64b/66b encoding/decoding algorithm is used so it will pass a descrambler and block-sync chip before it is able to be decoded. Depending on vendor implementation there are some variation at which point the actual decoding is done. Most of these cases the decoder will pull the 66 bits out of the elastic buffer and decodes these on the fly when the ASIC does a read request to that interface.
As you can see there are many points where things might go wrong and it is thanks due to the brilliance of these hardware engineers that a BER of 10^15 is fairly normal.
So going back to these SERDES defects Brocade and others have popped up. What do they mean. These settings are to adjust the pre-emphasis settings of the serdes chip in such a way that it will over-drive the first transition and gradually underdrives on each subsequent bit of the same polarity. Huhhhh, what does that mean???
The 8b/10b encoding/decoding schema makes sure you will never have more than 5 consecutive ones or 5 consecutive zeros in a bit stream. If you run into a long string of consecutive ones or zero you will run into a phenomenon called ISI (Inter Symbol Interference). This means the transmission path capacitance may be higher than the discharge capability of that circuit after a short transition. In plain English it means the circuit charges itself to a higher rate that it can discharge it at the next transition.
So lets visualise this.
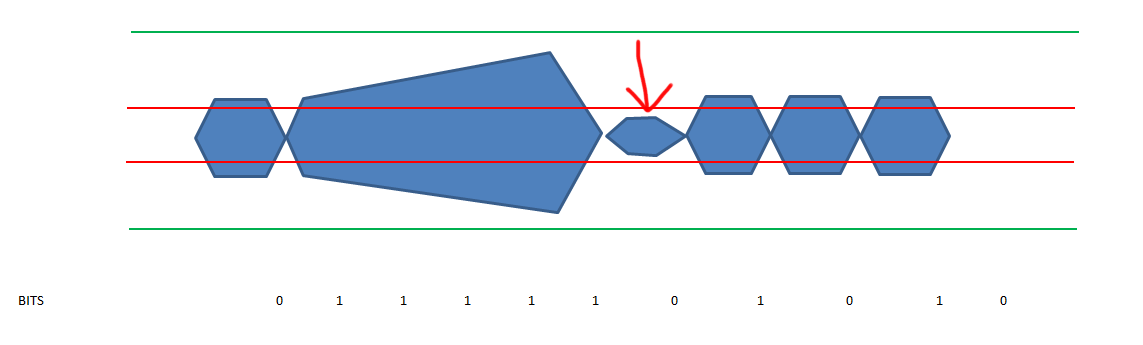
In the above picture the green line represents the upper and lower boundaries of the maximum voltage levels of the circuit and the red lines represent the upper and lower values were the end-point distinguishes between a 1 or a 0. (These are determined in the standards bodies of the respective interfaces. For Fibre Channel it is determined by the FC-PI-xx standard of the T11 committee). As you can see due to the over charge on the circuit after 5 ones the discharge on the transition is not big enough to fall outside the detection zone boundaries and thus the end-point is unable to detect a transition from 1 to 0 and thus it will result in an encoding error. There is a second problem with this and that is the fact of clock synchronization. There are two options for serdes chip to be able to synchronise the clock rate, SS or Source Synchronous and CDR (Clock Data Recovery). Source Synchronous requires a separate clock signal on the wire for the remote side to hook into whilst CDR is using a phase lock to the incoming bitstream and as such can adjust the clock-rate accordingly. (Remember the K28.5 ??) If however the transmission characteristics of this signal deter due to the ISI problem outlined above or any other issue the receiving side will lose synchronization and thus will need to first re-align itself again in order to be able to successfully be able to decode the bit stream. This will cause inflight frame to be lost and if the problem is persistent enough it will result in a severe performance problem or other nastiness.
With pre-emphasis the sending side will make sure there is a stepped degraded power-level on each subsequent bit and this will have the effect the capacitance value of the circuit will stay flat and the transition to the next different polarity will fall beyond the boundaries of the detection zone. An example of different pre-emphasis values show the effect on the eye-pattern below.
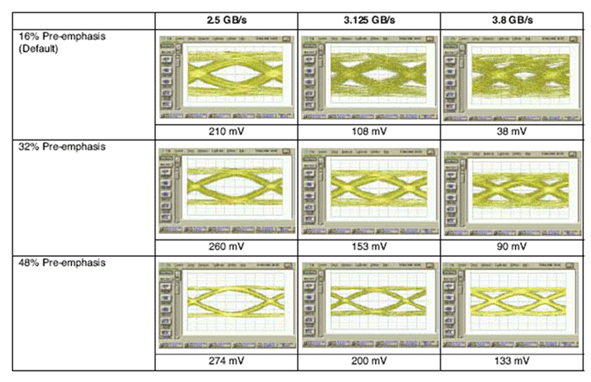
So when a vendor shows “defects” or “bugs” in relation to SERDES it does not mean there is really a hardware problem or software bug but more or less a way to track different settings on different ports to adjust the pre-emphasis values on those ports.
As you can imagine on a chassis with over 350 user ports and the even more ports on the back-end side of the fence there is a lot to track down and a change on one port may have a negative effect on other ports.
If we\’re dealing with Brocade switches or directors the actual values are stored in the ASIC registers which can be collected via a supportsave. If you don\’t know what you\’re looking for then don\’t even try. 🙂 There is also the option to adjust these values real-time however the previous comment is even more applicable. Unless you are a Brocade ASIC hardware engineer don\’t even try. I did modify some values in a controlled lab environment and YES, thing do go haywire when entering values you pulled out of the hat.
Testing, testing… one-two-three…. For some advanced features.
Testing for a faulty port is always a bit tricky since you first need to know what you\’re looking for and secondly you need to know what and how to interpret the outcome. Brocade has a utility in FOS called “portloopbacktest”. This utility allows you to test on a range of different options. the backdraw is that the switch needs to be in a non-operational (ie disabled) state.
If you’ve read the above you’ll see there are three distinct locations you need to test.
1. External to the SFP (ie the entire link including cabling, connectors, patch panels etc.)
2. External to the SERDES chip but before the SFP (ie internal ASIC/FPGA to SFP circuit)
3. Internal (parallel) to check for correct operation of encoding/decoding, elastic buffer, scrambler etc.
The below picture shows these three options. This is a snippet of a Virtex-II Pro RocketIO FPGA. You can see the layout of the TX and RX side with the SERDES chip, clock manager, encoder etc. Obviously depending on the vendor and usage you might see additional functionality being put into this like FEC calculators etc.
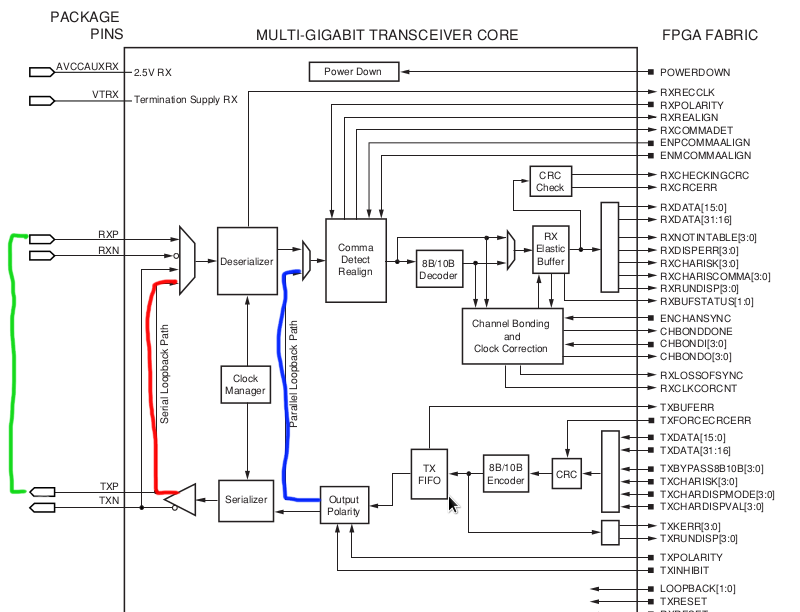
For option one you can use a loopback-plug directly on the SFP if you suspect a faulty laser or at the end of the link.
Normally you would start with the parallel test (Blue) and work your way up from there to the serial loopback (Red) and then the external one (Green). Also be aware the portloopbacktest uses a different port numbering schema than you might be accustomed to. This schema is based on the actual bladeport number according to the ASIC layout of the specific blade so it does not work based on the front-end port-numbers. This means that each blade type (16,32 or 48 port) will have a different numbering schema. Check the troubleshooting and command reference manual around these options.
On the 16G condor 3 hardware you can also use the new, so called, “D-Port” functionality. This however only works if you have two of these type of switches or 16G Brocade HBA\’s connected to these 16G switches. If you implement these switches and/or HBA\’s I would strongly suggest you test the link with this functionality as it can prevent future problems.
I hope this explains something around link errors you may find on fibre-channel ports and the cause plus resolution of it.
Let me know if you have further interest into different topics and I\’ll see what I can cook up. 🙂
Cheers,
Erwin
Hi Erwin, thanks for the excellent reading, even better than always.
Just as a side note about the D-Port functionality. Very good stuff, but still needs some … “tuning”. 1) I’ve seen D-Port reporting “PASSED” while some very bad counters increasing at one of the ends of the wire. 2) Occasional disabling of the D-Port might lead to the reset of the entire blade.
In theory that shouldn’t be happening however I’m not surprised since the “ClearLink” technology that Brocade developed is still in its infancy. Qlogic, after taking on the Brocade HBA business, will also further develop the ClearLink technology so I think within one or two years they will have an excellent understanding on how it all pans out. There haven’t been many cases around yet so both companies rely on their internal QA departments to figure out stuff. As soon more field experience is gained you see an improvement in code and use-cases. As for the blade-failure in some cases this is expected. If multiple ports on a back-end link observe errors FOS may fault a blade. Remember that front-end port-errors might be propagated to the back-end especially when Link-resets and/or CRC errors occur. Basically the name of the game is you have to make sure the physical side of the infrastructure is in 100% tip-top shape before taking it into production.
Thanks for your response.
Cheers, Erwin